This project provides a comprehensive guide to developing an API system for
extracting text from images, categorizing the content, and deploying a trained model for
automated processing. The aim is to ensure high accuracy, efficiency, and scalability.
Objective: Extract text from images with high accuracy.
● Best Practice: Use advanced OCR tools and preprocess images to enhance
clarity and text recognition.
1. Categorization of Extracted Text Objective:
● Assign extracted text to predefined categories.
2. Separating Training and Testing Data
Objective: Prepare the dataset for model training and evaluation.
● Best Practice: Ensure proportional representation of each category in training
and testing sets via stratified sampling.
3. Training and Testing the Model
Objective: Develop a predictive model for text categorization.
● Best Practice: Perform cross-validation, hyperparameter tuning, and apply
regularization techniques to build an effective model.
4. API Integration of the Trained Model
● Objective: Deploy the model into production through an API
This summary captures the key technical achievements and highlights mine skills in cloud technologies, microservices, and performance testing.
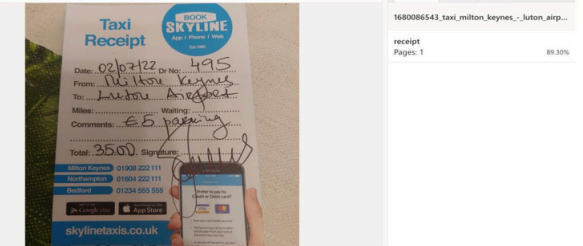
● Text Extraction Example: An image of a receipt is processed to extract and
digitize the text.
● Categorization Example: The extracted text "Flight from NY to SF" is categorized
under "Flight."
● Data Split Example: 20,000 labeled examples are used for training, and 5,000
are held back for testing, maintaining category ratios.
● Model Training Example: A neural network model is trained using the categorized
text data, achieving 85% accuracy.
● API Integration Example: The trained model is deployed as a Docker container
and exposed via an API endpoint for real-time categorization.