About us
Lorem ipsum dolor sit amet, consectetur elit, sed do eiusmod tempor incididunt ut labore et magna aliqua. Ut enim ad minim veniam laboris.
Lorem ipsum dolor sit amet, consectetur elit, sed do eiusmod tempor incididunt ut labore et magna aliqua. Ut enim ad minim veniam laboris.

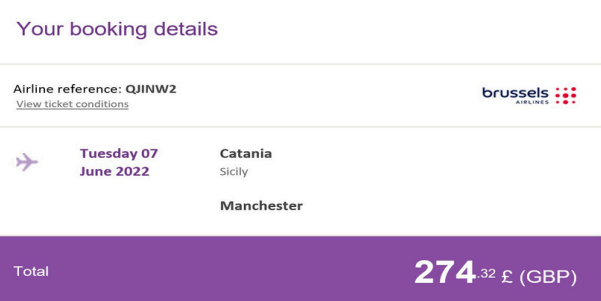
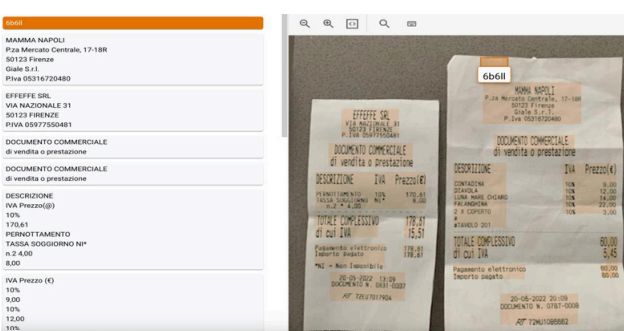
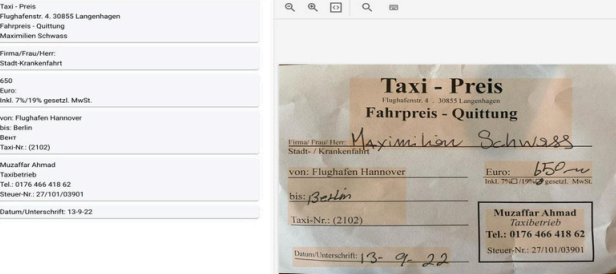
OCR stands for Optical Character Recognition,
a technology that converts different types of documents,
such as scanned paper documents, PDF files,
or images captured by a digital camera, into editable and searchable data.
This project provides a comprehensive guide to developing an API system for
extracting text from images, categorizing the content, and deploying a trained model for
automated processing. The aim is to ensure high accuracy, efficiency, and scalability.
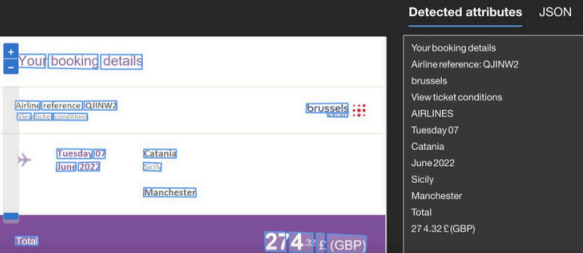
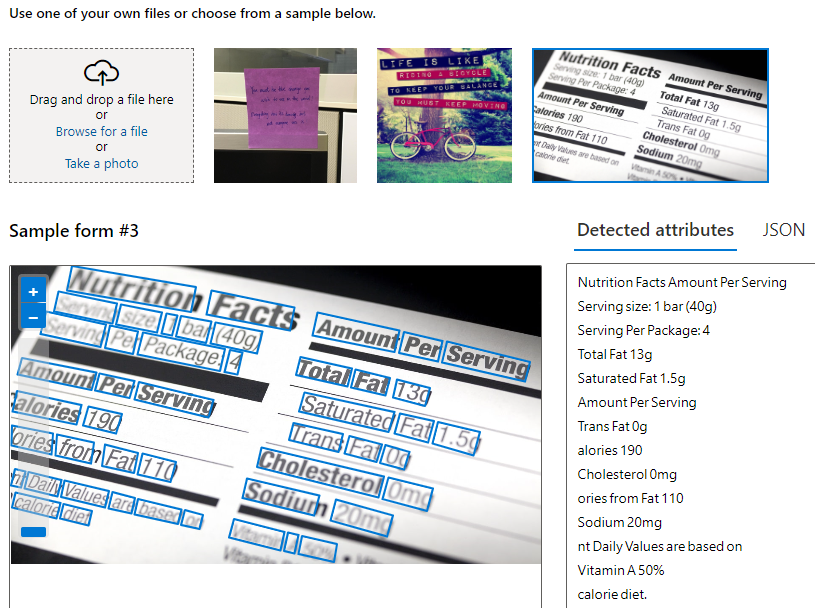
Objective: Extract text from images with high accuracy.
● Best Practice: Use advanced OCR tools and preprocess images to enhance
clarity and text recognition.
This summary captures the key technical achievements and highlights mine skills in cloud technologies, microservices, and performance testing.
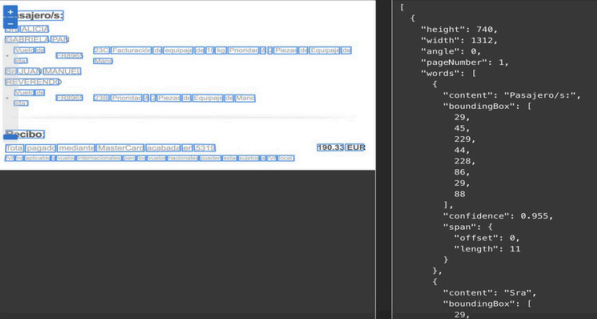
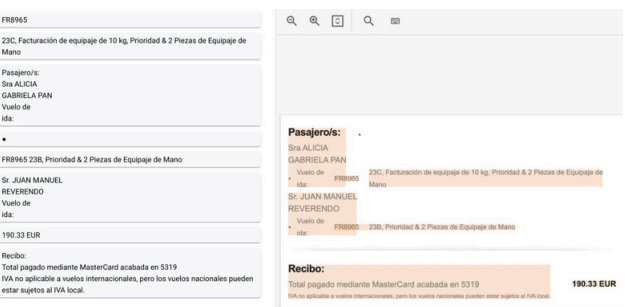
In this project, I developed a microservices architecture to automate the process of detecting and classifying text from images using leading cloud-based OCR technologies, including Azure Vision OCR and Google Cloud AI OCR, alongside Azure Vision Classification. The project processed a dataset of over 6,000 images, extracting textual content from each image and storing the results in JSON files for further classification. The first phase of the project focused on the precise extraction of text using Azure and Google Cloud OCR services, ensuring high accuracy even with varied fonts, layouts, and image qualities. The extracted text was later used for classification, enabling categorization of the images based on their textual content.